
Don't Trust AI Models responses? CRITIC Ensures LLM Trustworthiness
AI Agentic Design Pattern: CRITIC


While interacting with Large Language Models (LLMs) one thing that you should keep in mind, that sometimes the response received to your prompt may be flawed, factually incorrect, completely made up or even offensive or harmful to others in some cases.
Unlike these AI models in our human lives we fact check information from trusted external sources like Wikipedia, searching through internet or using a debugging tool in case of code, to make sure we set things right.
Inspired from this human behavior Self-Correcting with Tool-Interactive Critiquing (CRITIC) is a framework that lets these black-box AI models validate the information and improve their own output by interacting with external tools such as a search engine, just like humans do.
The CRITIC Process
In Figure below for an input, LLMs first generate an initial output based on parametric knowledge it has, then interact with appropriate external tools through text-to-text APIs to verify the output. The critiques generated by the verification step are concatenated with the initial output, and serve as feedback to allow LLMs to correct the output. The cycle of “Verify ⇒ Correct ⇒ Verify” iterates continuously to improve the output until a specific stopping condition is met.
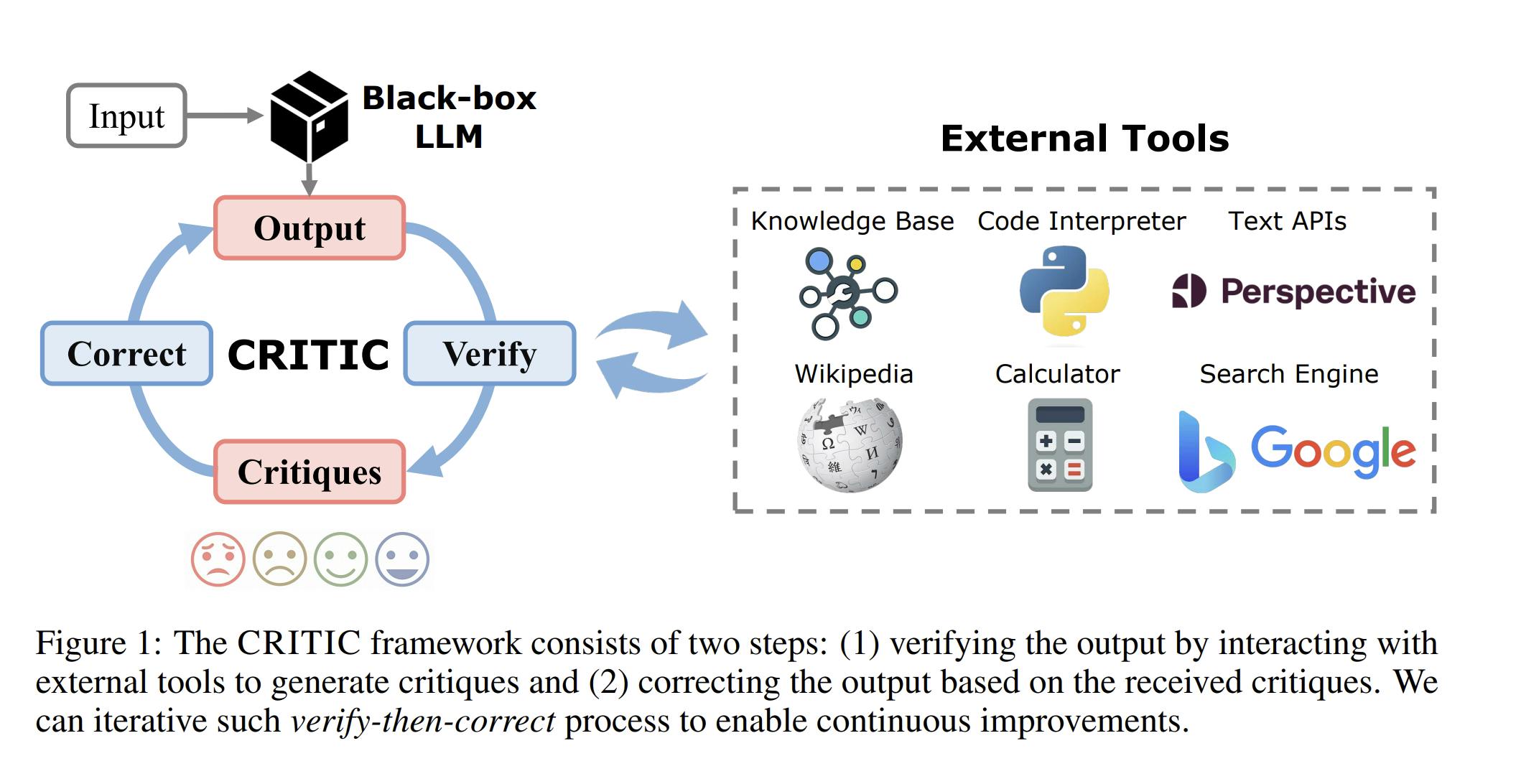
The language model outputs an initial answer to a question or task given in the prompt.
CRITIC then interacts with "external tools" to check and verify that answer. For example, it might use a search engine to look up information and see if the answer is accurate and truthful.
Based on the feedback from the tools, CRITIC identifies any problems or mistakes in the original answer.
CRITIC then takes that feedback and uses it to help the language model generate an improved, corrected answer.
This process can be repeated multiple times, with the language model continually refining its answer based on the external feedback until a stopping condition is met.
Benefits of CRITIC
It helps the language model catch and fix its own mistakes, without relying on expensive human annotations or additional training.
It allows the model to learn from interactions with the real world, rather than just its own internal knowledge.
It makes the language model's outputs more reliable and trustworthy, by verifying the information against external sources.
Conclusion
Overall, CRITIC acts like a coach, giving the language model feedback to help improve its answers, rather than just accepting the first output instance. This makes LLMs more reliable and trustworthy by giving them a way to check their answers and fix any errors. This makes the language model smarter and more reliable over time.
Source
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing